樣本量估算是臨床試驗設計中極其重要的環節,根據統計學原則確定的樣本量,是預期檢驗假設能夠得到確證所需的最小樣本量。準確地估計樣本量是臨床試驗得以有效進行的保證。隨機對照試驗設計是臨床試驗設計的金標準,在藥物/醫療器械臨床試驗中被廣泛采用,但在少數醫療器械臨床試驗中,由于倫理學原因、臨床操作可行性或其他原因,很難進行隨機對照的臨床試驗。此時,單組目標值臨床試驗可視為一種替代策略,為產品注冊提供關鍵證據。本文將對醫療器械單組目標值試驗樣本量估算相關疑問進行解答。單組目標值臨床試驗中沒有為試驗組設立傳統意義上的同期對照組,而是采用目標值作為理論對照值,將試驗結果與理論值進行比較。但需注意試驗設計時,為保證單組目標值法研究結果的科學性,使得當前試驗所獲得的結果與同類產品的外部對照具有可比性,需建立在特定的適應癥、入選/排除標準、主要療效評價指標及評價時間點等基礎上。目標值應在研究方案設計階段由申辦方、臨床研究者和統計學家共同制定,因目標值還將在試驗結束后用來評價試驗結果是否滿足研究假設,故需在方案中詳述目標值的確定依據。目標值確定常用方式有三種,但無論采用何種方法確定目標值,均建議事先與臨床監管部門進行溝通,達成共識后方可開始臨床試驗。優先考慮監管部門指南中確定的目標值。如果該類產品指導原則中明確寫明,可采用單組目標值法進行臨床試驗,且指南中對主要評價指標給出了明確的目標值。在此種情況下,可將指南推薦的目標值作為該產品臨床試驗主要評價指標的目標值。如果監管部門沒有出臺相關指導原則,則考慮行業標準或專家共識。即參考該產品所屬專業領域公認的行業標準或公開發表的專家共識中給出的該產品主要評價指標所應達到的療效或安全性水平,并以此水平作為目標值。可參考的行業標準包括但不限于ISO標準、國標、行標或部標等。上述兩種情況均不適用時,則考慮同類產品歷史研究結果的綜合作為目標值確定依據。如具有可比性的同類產品所進行的臨床試驗結果的系統綜述和meta分析結果。臨床試驗的樣本量通常是依據對主要評價指標做出相應的假定后進行估計。方案中主要評價指標的含義、測量方法和時間點、計算方法都應當準確定義,在檢索參考資料時應當注意主要指標定義是否與方案一致,避免出現“同名不同義”的情況。比如某方案的“治療有效率”的評價時間點為干預后2周,隨訪時間越長治療有效率越高,但是參考資料中同為“治療有效率”但評價時間點為干預后3周,如果采用這個參考資料來估算樣本量,可能會高估產品的療效,在其他參數不變的情況下,計算出較少的樣本量,最終可能因為把握度不足導致假設檢驗不成立。另外,還需要考慮參考資料產品的功能、性質等是否與本試驗產品一致。大多數情況下主要評價指標一般只有一個,有些臨床試驗會設計兩個或多個主要評價指標,此時需要注意假設檢驗的多重性問題,考慮調整參數α、β。檢驗水準:用α表示,也就是第Ⅰ類錯誤概率,常取單側0.025。涉及多重性問題、期中分析時,會考慮對α進行調整。
檢驗效能:也叫把握度,用1-β表示,β代表第Ⅱ類錯誤概率。檢驗效能是指在設定的α基礎上,原假設H0為假且檢驗結果拒絕了H0的概率。檢驗效能越高,發現差異的可能性越大,但同時所需樣本量也越大。在臨床試驗中,檢驗效能不能低于80%。
脫落率:由以上公式估算出的樣本量是在給定條件下滿足臨床試驗所需的最小樣本量。在實際試驗過程中,由于不良反應、受試者依從性差等原因,會導致受試者脫落。因此,需要在樣本量估計的基礎上適度地擴大樣本量以保證最終的有效樣本量可以滿足最小樣本量的需求。脫落率通常不應超過20%,特殊情況需另外判斷。
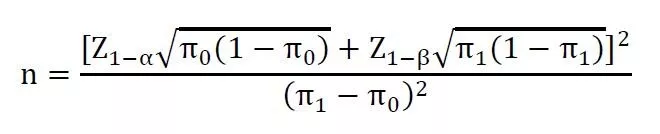
其中,Z1-α和Z1-β表示標準正態分布中對應的1-α和1-β的分位數。π1為被試產品主要評價指標的預期值,π0為目標值。例如,在一項單組目標值臨床試驗中,主要評價指標為有效率,根據相關參考文獻,估計某試驗產品預期有效率為95%,目標值為90%。設α=0.025(單側),β=0.20,脫落率為20%,則該試驗所需樣本量為:
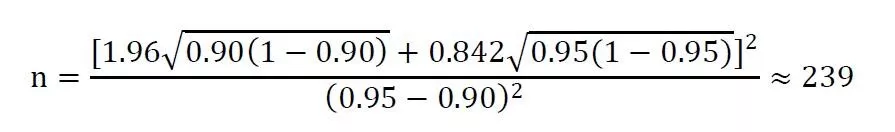
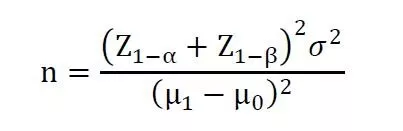
其中,Z1-α和Z1-β表示標準正態分布中對應的1-α和1-β的分位數。μ1為被試產品預期主要評價指標的總體均數,σ為主要評價指標的標準差,μ0為目標值。同上代入數據進行計算即可得出對應試驗所需樣本量。[1]陳峰,夏結來.臨床試驗統計學[M]. 人民衛生出版社, 2018.[2]王楊,胡泊,陳濤,et al.抽樣調查法和單組目標值法對診斷試驗樣本量計算差異的分析[J].Chinese journal of Epidemiology,2010,31(12):1403-1405.
作者:奧咨達醫療器械服務集團 臨床研究事業部
 中國臨床服務
中國臨床服務 
